疫情还没有解除。开学不能返校,所以只能在家里上课学习。实验室的正式任务也已经开始了。寒假布置的任务是学习并行计算的相关知识,和学习Linux系统下的编程(vim),以及多线程OpenMP语言。
进入正题之前总是想要碎碎念一下。毕竟我的博客也不是当作技术教程来写的,更多的是想当成自己的一个小天地,记录一下一直以来我的学习历程。过几年再回头来看,说不定就是一个普通计算机专业大学生进化为前沿技术科研工作者/技术大牛/高级工程师的学习史嘿嘿~
Anyway,这篇博客想要记录的是 对于我来说 一个全新的模块 并行计算相关
最让我头疼的就是并行粒度问题了,当一个程序串行执行时只需9s,你使用多线程并行后变成了30s↑。 初学者怀疑人生系列。
OpenMP基础
OpenMP是基于共享存储体系的一个并行编程标准。通过在串行程序中添加OpenMP指令和调用OpenMP库函数来实现在共享内存系统上的并行执行。可以在超级计算机上执行,具有良好的可移植性。
- 不打开OpenMP编译选项,编译器将忽略OpenMP指令。
- 并行线程数可以在程序启动时利用环境变量设置。
- 支持与MPI混合编程
OpenMP并行程序的编写方法
增量并行: 逐步改造现有的串行程序,每次只对部分代码进行并行化,这样可以逐步改造,逐步调试。
OpenMP编程要素
制导指令和子句按照各自的功能可以大致分为四类:
并行域指令 Parallel Constructs
parallel
end parallel:
标志一个并行域的开始和结束。
工作共享指令
Do ,end Do (Fortran): 用在Do循环之前,标识一个并行循环任务的开始和结束,必须保证每次循环之间无数据相关性。
sections
section :标识仅由一个线程执行的若干区域。
end section
Single: 标识经由一个线程执行的区域。
其中一种需要使用single制导指令的情况是为了减少并行域的创建和开销,而将多个临近的parallel并行域合并时。经过合并后,原来并行域之间的串行代码也将被并行执行,违反了代码原来的目的,因此这部分代码可以用single指令加以约束只用一个线程来完成。
同步指令
Openmp支持两种不同类型的线程同步机制,一种是互斥锁的机制,可以用来保护一块共享的存储空间,使任何时候访问这块共享内存空间的线程最多只有一个,从而保证了数据的完整性;另一种机制是事件同步机制,这种机制保证了多个线程制之间的执行顺序。
master:标识仅由主线程执行的区域的开始
critical: 标识关键区的开始(保证每次只有一个线程进入)
barrier: 障碍同步
atomic: 确保共享变量在同一时间只能被一个线程更新。值得注意的是,当对一个数据进行原子操作保护的时候,就不能对数据进行临界区(critical)的保护,openmp运行时并不能在这两种保护机制之间建立配合机制。用户在针对同一个内存单元使用原子操作的时候,需要在程序所有涉及到该变量并行赋值的部位都加入原子操作的保护。
flush: 用在同步的时候,确保数据被正确写入
ordered: 指定并行区域的循环按顺序执行。有些任务在并行执行,对于部分必须串行执行的部分才启用ordered保护。
子句[cluse]
private、firstprivate、lastprivate、reduction、nowait、
num_threads、schedule、shared、copyprivate、copyin、default。
注意:
①如果存在写操作,必须对共享变量加以保护,否则不要轻易使用共享变量,尽量将共享变量的访问转化为私有变量的访问。循环迭代变量在循环构造的任务分担域里是私有的,声明在任务分担域内的自动变量都是私有的。
②出现在reduction子句中的变量不能出现在private子句中。
③如果在并行域内不加锁保护就直接对共享变量进行写操作,存在数据竞争问题,会导致不可预测的异常结果。如果共享数据作为private、firstprivate、lastprivate、threadprivate、reduction子句的参数进入并行域后,就变成线程私有了,不需要加锁保护了。
④对于lastprivate子句,如果是for循环迭代,那么是将最后一次的循环迭代中的值赋给对应的共享变量;如果是sections构造,那么是代码中排在最后的section语句中的值赋给对应的共享变量。
⑤ threadprivate与copyin关联进行初始化,copyprivate与single关联进行广播
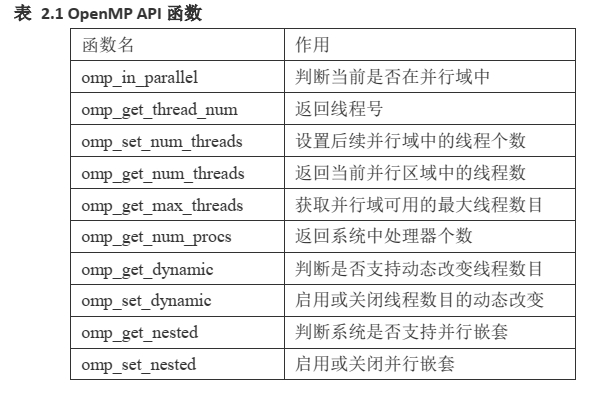
API函数
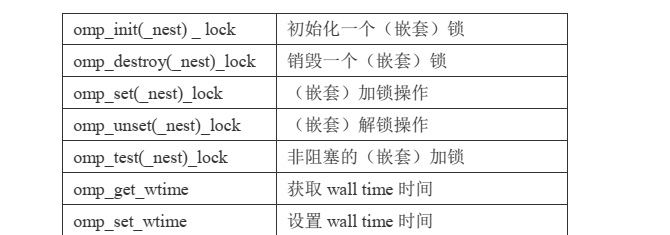
锁
锁的消耗是介于 atomic 和 critial 之间的,锁操作特别灵活,当另外两种方式不能满足需求时可以考虑通过锁来实现。
锁的类型为omp_lock_t,相关函 数有:omp_init_lock(初始化锁)、omp_set_lock(获得锁)、omp_unset_lock (释放锁)以及 omp_destroyed_lock(销毁锁)。
初始化锁和销毁 锁要在并行区域之外进行。
schedule
(static/dynamic/guided/runtime,[size])
static:静态调度策略,将任务/数据在循环执行之前被分配给线程。采 用交替分配的方式按照 size 大小来给每个线程分配迭代。
使用动态调度规则时,需要考虑任务分配所花费的时间更多
dynamic:动态调度策略,任务/数据在循环执行时被分配给线程。当线 程计算完成时,它能够从运行时系统中请求更多。
guided:指导调度策略,也是任务/数据在循环执行时被分配给线程。它采用启发式自调度策略。开始时每个线程会被分配较大的迭代次数,之后逐渐减小。
runtime:运行时调度策略,在运行时根据环境变量的值来决定具体的
调度策略,使用上述三种中的一种。
三种调度策略的系统开销大小依次是 static < dynamic < guided。如果代码在默认情况下(不使用 schedule)能达到较好性能,则不使用 schedule 子句。如果随着循环的进行,迭代的计算量线性递增(或递减),采用 size 较小的 static 策略能得到较好的负载均衡,提供最好的性能。动态调度时,size较小有利于实现更好的负载平衡,但是会引起过多的任务动态申请开销,反之size大则开销较少,但不易于实现负载平衡,size的选择需要在这两者之间进行权衡。如果需要在多种策略之间对比测试时,可以考虑使用 runtime 方式通过环境变量来控制最终使用哪一种策略,避免反复变动代码。
指令for任务分担
循环变量分解原则:
- 分解代价低
- 任务的计算量要均衡
- 尽量避免cache行冲突
首先需要时间上快速分解方案产生方法,任务划分开销最低的是静态分割方法。所以因尽量使用静态调度。
其次要求分解方案产生的各个计算任务负载均衡。
第三个原则是循环变量划分方案尽量能让各个线程执行for循环体的代码时,充分考虑其中的代码访问和数据访问顺序与cache的关系。




